






Р’ СҖСғРұСҖРёРәСғ "All-over-IP" | Рҡ СҒРҝРёСҒРәСғ СҖСғРұСҖРёРә | Рҡ СҒРҝРёСҒРәСғ авСӮРҫСҖРҫРІ | Рҡ СҒРҝРёСҒРәСғ РҝСғРұлиРәР°СҶРёР№

РһРҙРҪРҫ РёР· важРҪРөР№СҲРёС… РҪР°РҝСҖавлРөРҪРёР№ РІРҪРөРҙСҖРөРҪРёР№, РіРҙРө РұСғРҙСғСӮ РҫСҒРҫРұРөРҪРҪРҫ РҝРҫР»РөР·РҪСӢ РҪРөР№СҖРҫРҪРҪСӢРө СҒРөСӮРё вҖ“ СҚСӮРҫ СҖРөСҲРөРҪРёРө Р·Р°РҙР°СҮ РІРёРҙРөРҫР°РҪалиСӮРёРәРё РҙР»СҸ "Р‘РөР·РҫРҝР°СҒРҪРҫРіРҫ РіРҫСҖРҫРҙР°". РЈР¶Рө СҒРөРіРҫРҙРҪСҸ СҒСғСүРөСҒСӮРІСғСҺСӮ алгРҫСҖРёСӮРјСӢ, СҖР°РұРҫСӮР°СҺСүРёРө РҪР° РіР»СғРұРҫРәРёС… РҪРөР№СҖРҫРҪРҪСӢС… СҒРөСӮСҸС… (СҖР°СҒРҝРҫР·РҪаваРҪРёРө лиСҶР°, СҮРөР»РҫРІРөРәР° Рё РҙСҖ.), РәРҫСӮРҫСҖСӢРө РјРҫР¶РҪРҫ вживиСӮСҢ РҪР° СҮРёРҝ РҪР° РұРҫСҖСӮСғ РәамРөСҖСӢ.
РһРұСӢСҮРҪСӢРө РҝРҫР»РҪРҫСҒРІСҸР·РҪСӢРө СҒРөСӮРё СҒСғСүРөСҒСӮРІРҫвали СҒ РҙавРҪРёС… РІСҖРөРјРөРҪ. Р’ 1988 Рі. РұСӢли РҝСҖРёРҙСғРјР°РҪСӢ РәРҫРҪРІРҫР»СҺСҶРёРҫРҪРҪСӢРө (СҒРІРөСҖСӮРҫСҮРҪСӢРө) СҒРөСӮРё, Р° РҫСӮРҙРөР»СҢРҪРҫ РҫСӮ РҪРёС… РІ 2006 Рі. вҖ“ РіР»СғРұРҫРәРёРө СҒРөСӮРё.
Р РөРІРҫР»СҺСҶРёСҸ РІ РјР°СҲРёРҪРҪРҫРј Р·СҖРөРҪРёРё СҒР»СғСҮилаСҒСҢ РІ 2011 Рі., РәРҫРіРҙР° РұСӢли СҒРҫРұСҖР°РҪСӢ РІ РҝРөСҖРІРҫРј РІРёРҙРө РіР»СғРұРҫРәРёРө СҒРөСӮРё РҙР»СҸ Р·Р°РҙР°СҮ РјР°СҲРёРҪРҪРҫРіРҫ Р·СҖРөРҪРёСҸ Рё РҝСҖРҫСҲла РҝРөСҖРІР°СҸ РІРҫР»РҪР° РҝСғРұлиРәР°СҶРёР№ Рҫ РіР»СғРұРҫРәРёС… СҒРІРөСҖСӮРҫСҮРҪСӢС… РҪРөР№СҖРҫРҪРҪСӢС… СҒРөСӮСҸС… РІ СҖР°СҒРҝРҫР·РҪаваРҪРёРё РёР·РҫРұСҖажРөРҪРёР№.

РҡР»СҺСҮРөРІСӢРө РҝР»СҺСҒСӢ СӮР°РәРёС… СҒРөСӮРөР№:
РЈ РҪРөР№СҖРҫРҪРҪСӢС… СҒРөСӮРөР№ РөСҒСӮСҢ Рё РјРёРҪСғСҒСӢ:
РқР°СҮРёРҪР°СҸ СҒ 2015 Рі. РҪР° РІСҒРөС… РҫРұСүРөРҙРҫСҒСӮСғРҝРҪСӢС… Рұазах РұСӢР» СҒРҫРІРөСҖСҲРөРҪ Р·РҪР°СҮРёСӮРөР»СҢРҪСӢР№ СҖСӢРІРҫРә РІ СҖР°СҒРҝРҫР·РҪаваРҪРёРё, Рё РјРҫР¶РҪРҫ СғСӮРІРөСҖР¶РҙР°СӮСҢ, СҮСӮРҫ Р»СғСҮСҲРёРө СҖРҫСҒСҒРёР№СҒРәРёРө СҒРёСҒСӮРөРјСӢ СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ лиСҶ СҸРІР»СҸСҺСӮСҒСҸ Рё Р»СғСҮСҲРёРјРё РІ РјРёСҖРө вҖ“ СӮСҖРё СҖРҫСҒСҒРёР№СҒРәРёРө РәРҫРјРҝР°РҪРёРё РІС…РҫРҙСҸСӮ РІ СӮРҫРҝ-5 РҝРҫ РұазРө NIST. Р•СҒли СҖР°РҪСҢСҲРө РјРҫР¶РҪРҫ РұСӢР»Рҫ СҖР°СҒРҝРҫР·РҪР°СӮСҢ лиСҶРҫ СӮРҫР»СҢРәРҫ РІРҫ С„СҖРҫРҪСӮалСҢРҪРҫРј СҖР°РәСғСҖСҒРө, СӮРҫ СҒРөР№СҮР°СҒ СҚСӮРҫ РІРҫР·РјРҫР¶РҪРҫ СҒРҙРөлаСӮСҢ РҝСҖР°РәСӮРёСҮРөСҒРәРё РІРҫ РІСҒРөС… СҖР°РәСғСҖСҒах.
РҡлаСҒСҒРёСҮРөСҒРәРёРө СҒРёСҒСӮРөРјСӢ СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ РҝРҫСҒСӮСҖРҫРөРҪСӢ РҪР° РҝСҖРөРҙРІР°СҖРёСӮРөР»СҢРҪСӢС… РҝСҖРөРҙРҝРҫР»РҫР¶РөРҪРёСҸС…: РјРҫРҙРөлиСҖРҫРІР°РҪРёРө С„РҫРҪР°, СҖазРҙРөР»РөРҪРёРө Foreground Рё Background (РҪРөРҝРҫРҙРІРёР¶РҪСӢР№ С„РҫРҪ Рё РҙРІРёР¶СғСүРёРөСҒСҸ РҫРұСҠРөРәСӮСӢ РҪР° РҪРөРј). РқРҫ СҚСӮРҫ РҝСҖРҫСӮРёРІРҫСҖРөСҮРёСӮ РІРҫСҒРҝСҖРёСҸСӮРёСҺ СҮРөР»РҫРІРөРәР°, СӮР°Рә РәР°Рә СҮРөР»РҫРІРөРә Рё РұРөР· РҝСҖРёР·РҪР°РәР° РҙРІРёР¶РөРҪРёСҸ РјРҫР¶РөСӮ Р»РөРіРәРҫ РҫРҝСҖРөРҙРөлиСӮСҢ Р»СҺРҙРөР№, РҪахРҫРҙСҸСүРёС…СҒСҸ РІ РөРіРҫ РҝРҫР»Рө Р·СҖРөРҪРёСҸ. РЎРөР№СҮР°СҒ РҝСҖРҫРёСҒС…РҫРҙРёСӮ РҝРөСҖРөС…РҫРҙ РҫСӮ РҝСҖРөРҙРҝРҫР»РҫР¶РөРҪРёР№ Рҫ СҒСҶРөРҪРө РёРјРөРҪРҪРҫ Рә СҖР°СҒРҝРҫР·РҪаваРҪРёСҺ РҫСӮРҙРөР»СҢРҪСӢС… РҫРұСҠРөРәСӮРҫРІ Рё РёСҒРҝРҫР»СҢР·СғСҺСӮСҒСҸ РҪРө РҝСҖРёР·РҪР°РәРё РҙРІРёР¶РөРҪРёСҸ, Р° СӮРҫР»СҢРәРҫ фаРәСӮ РҪалиСҮРёСҸ РҫРұСҠРөРәСӮР° СӮРёРҝР° "СҮРөР»РҫРІРөРә РҪР° СҒСҶРөРҪРө". РЎРөРіРҫРҙРҪСҸ РІРөСҖРҫСҸСӮРҪРҫСҒСӮСҢ СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ СҒРёР»СғСҚСӮР° СҮРөР»РҫРІРөРәР° СғР¶Рө РҫСҮРөРҪСҢ С…РҫСҖРҫСҲР°СҸ вҖ“ РҫСҲРёРұРәРё 1-РіРҫ Рё 2-РіРҫ СҖРҫРҙР° СҒРҫСҒСӮавлСҸСҺСӮ РҝРҫСҖСҸРҙРәР° 1% РҪР° РҙР°РҪРҪСӢС… СҒСҖРөРҙРҪРөРіРҫ Рё РІСӢСҒРҫРәРҫРіРҫ РәР°СҮРөСҒСӮРІР°.
Р—Р°РҙР°СҮР° СҖРөРёРҙРөРҪСӮифиРәР°СҶРёРё РјРҫР¶РөСӮ РұСӢСӮСҢ СҖРөСҲРөРҪР° РІРҫ РјРҪРҫРіРёС… СҒРҝРөРәСӮСҖах.
РҹРөСҖРІСӢР№ (РҫСҮРөРІРёРҙРҪСӢР№, РҪРҫ СҖРөРҙРәРҫ Р·Р°РҝСҖР°СҲРёРІР°РөРјСӢР№ Р·Р°РәазСҮРёРәРҫРј) вҖ“ СҚСӮРҫ РҝРөСҖРөРҙР°СҮР° СҮРөР»РҫРІРөРәР° или РҙСҖСғРіРҫРіРҫ РҫРұСҠРөРәСӮР° РІРёРҙРөРҫРҪР°РұР»СҺРҙРөРҪРёСҸ РҫСӮ РҫРҙРҪРҫР№ РәамРөСҖСӢ Рә РҙСҖСғРіРҫР№, РәРҫРіРҙР° РөРіРҫ РҪСғР¶РҪРҫ РҝРҫРҙС…РІР°СӮРёСӮСҢ СҒ СӮРөРј Р¶Рө ID, СҒ РәРҫСӮРҫСҖСӢРј РҫРҪ РҙвигалСҒСҸ РҙРҫ СҚСӮРҫРіРҫ. Р Р°РҪСҢСҲРө СҚСӮР° Р·Р°РҙР°СҮР° РІ РҫРҝСҖРөРҙРөР»РөРҪРҪРҫР№ СҒСӮРөРҝРөРҪРё СҖРөСҲалаСҒСҢ, РҪРҫ РөСҒли СҮРөР»РҫРІРөРә РҪР° РҫРҙРҪРҫР№ РәамРөСҖРө РұСӢР» РІ РҫРҙРҪРҫРј СҖР°РәСғСҖСҒРө, Р° РҪР° СҒР»РөРҙСғСҺСүРөР№ вҖ“ СғР¶Рө РІ РҪРҫРІРҫРј, СӮРҫ РҪРө РІСҒРө алгРҫСҖРёСӮРјСӢ РёРҙРөРҪСӮифиРәР°СҶРёРё С…РҫСҖРҫСҲРҫ СҒРҝСҖавлСҸлиСҒСҢ. Р’СӮРҫСҖРҫР№ вҖ“ РҝРҫРёСҒРә СҮРөР»РҫРІРөРәР° или РҙСҖСғРіРҫРіРҫ РҫРұСҠРөРәСӮР° РІ РұазРө РҙР°РҪРҪСӢС… РҝРҫ РҫРҝРёСҒР°РҪРёСҺ, СҒС„РҫСҖРјРёСҖРҫРІР°РҪРҪРҫРјСғ РҫРҝРөСҖР°СӮРҫСҖРҫРј, или С„РҫСӮРҫРіСҖафии.

РЎРөР№СҮР°СҒ РҝРҫРҙС…РҫРҙ Рә СҖРөРёРҙРөРҪСӮифиРәР°СҶРёРё РҝРҫСҒСӮСҖРҫРөРҪ РҪР° РіРөРҪРөСҖР°СҶРёРё Deep ID РҙР»СҸ РҫРұСҠРөРәСӮР° (СҮРөР»РҫРІРөРәР°, авСӮРҫРјРҫРұРёР»СҸ Рё РҙСҖ.) СҒ РҝРҫСҒР»РөРҙСғСҺСүРёРј СҒСҖавРҪРөРҪРёРөРј СҲР°РұР»РҫРҪР° СҒ СҲР°РұР»РҫРҪами РҙСҖСғРіРёС… РҫРұСҠРөРәСӮРҫРІ (РәРҫРҪСӮСҖР°СҒСӮРҪСӢРө, СҶРІРөСӮРҫРІСӢРө РҝСҖРёР·РҪР°РәРё Рё СӮ.Рҙ.). Р‘РҫР»РөРө СӮРҫРіРҫ, РјРҫР¶РҪРҫ СҖР°СҒСҒРјР°СӮСҖРёРІР°СӮСҢ РҫРұСҖаз СҮРөР»РҫРІРөРәР° РәР°Рә лиСҶРҫ РҝСҖРё СҖР°СҒРҝРҫР·РҪаваРҪРёРё вҖ“ СӮРҫ РөСҒСӮСҢ СҲР°РұР»РҫРҪСӢ РІРҪРөСҲРҪРөРіРҫ РІРёРҙР° Р»СҺРҙРөР№ загСҖСғжаСҺСӮСҒСҸ РІ РұазСғ РҙР°РҪРҪСӢС… Рё РҝРҫСҒР»Рө РәРҫРҪРәСҖРөСӮРҪРҫРіРҫ СҒРҫРұСӢСӮРёСҸ, РөСҒли РҪСғР¶РҪРҫ РҝСҖРҫРұРёСӮСҢ РҫРұСҖаз СҮРөР»РҫРІРөРәР° РҝРҫ РұазРө РҙР°РҪРҪСӢС…, РҝРҫ РҪРөРјСғ СҒСӮСҖРҫРёСӮСҒСҸ Deep ID, СҒСҖавРҪРёРІР°РөСӮСҒСҸ СҒ СҲР°РұР»РҫРҪами, Рё РІСӢРҙР°СҺСӮСҒСҸ РІСҒРө РІС…РҫР¶РҙРөРҪРёСҸ СҮРөР»РҫРІРөРәР°, РҪРҫ РҪРө РҝРҫ лиСҶСғ, Р° РҝРҫ РІРҪРөСҲРҪРөРјСғ РІРёРҙСғ. РӯСӮРҫСӮ СҒРҝРөРәСӮСҖ Р·Р°РҙР°СҮ РёРҙРөРҪСӮифиРәР°СҶРёРё СҒРёР»СҢРҪРҫ РІСӢСҖРҫСҒ Рё СғР¶Рө СҒСӮал РҝРҫ-РҪР°СҒСӮРҫСҸСүРөРјСғ СғРјРҪСӢРј.
Р’РҫР·СҖРҫСҒли Р·Р°РҝСҖРҫСҒСӢ РҪР° авСӮРҫРјР°СӮРёСҮРөСҒРәРёРө СҒРёСҒСӮРөРјСӢ РҝСҖРҫРјСӢСҲР»РөРҪРҪРҫР№ РұРөР·РҫРҝР°СҒРҪРҫСҒСӮРё РІ СҮР°СҒСӮРё РҪРҫСҲРөРҪРёСҸ СҒСҖРөРҙСҒСӮРІ РёРҪРҙРёРІРёРҙСғалСҢРҪРҫР№ Р·Р°СүРёСӮСӢ. Р’РөСҖРҫСҸСӮРҪРҫ, СҚСӮРҫ СҒРІСҸР·Р°РҪРҫ СҒ РұРҫР»СҢСҲРёРјРё СҲСӮСҖафами, РҪР°РәлаРҙСӢРІР°РөРјСӢРјРё РҪР° СӮРө РҝСҖРөРҙРҝСҖРёСҸСӮРёСҸ, РәРҫСӮРҫСҖСӢРө РҪРө РҫРұРөСҒРҝРөСҮРёРІР°СҺСӮ РҪРҫСҲРөРҪРёРө РЎРҳР— РҪР° РҝСҖРҫРёР·РІРҫРҙСҒСӮРІРө. РһРҝРөСҖР°СӮРҫСҖСғ Р¶Рө СҒРёСҒСӮРөРјСӢ РІРёРҙРөРҫРҪР°РұР»СҺРҙРөРҪРёСҸ РҫСӮСҒР»РөРҙРёСӮСҢ фаРәСӮ РҫСӮСҒСғСӮСҒСӮРІРёСҸ РЎРҳР— РҙРҫРІРҫР»СҢРҪРҫ СҒР»РҫР¶РҪРҫ.

ГлСғРұРҫРәРёРө РҪРөР№СҖРҫРҪРҪСӢРө СҒРөСӮРё СҒРҝСҖавлСҸСҺСӮСҒСҸ Рё СҒ СӮР°РәРҫР№ Р·Р°РҙР°СҮРөР№ вҖ“ РҝРҫ РәажРҙРҫРјСғ СӮРёРҝСғ СғРҪРёС„РҫСҖРјСӢ СҒРёСҒСӮРөРјСғ РҝСҖРёРҙРөСӮСҒСҸ РҙРҫСғСҮРёСӮСҢ, РҪРҫ СҖРөР·СғР»СҢСӮР°СӮСӢ СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ РІСӢСҒРҫРәРё РҙажРө РҙР»СҸ СӮР°РәРёС… СҒСҖРөРҙСҒСӮРІ РёРҪРҙРёРІРёРҙСғалСҢРҪРҫР№ Р·Р°СүРёСӮСӢ, РәР°Рә РҫСҮРәРё, РҝСҖРёСҮРөРј РҪР° СҒСҖавРҪРёСӮРөР»СҢРҪРҫ РҪРөРұРҫР»СҢСҲРёС… СҖазСҖРөСҲРөРҪРёСҸС…, вҖ“ РҫСҲРёРұРәРё 1-РіРҫ Рё 2-РіРҫ СҖРҫРҙР° СҒРҫСҒСӮавлСҸСҺСӮ РҝРҫСҖСҸРҙРәР° 5%.
РЎ СӮРҫСҮРәРё Р·СҖРөРҪРёСҸ РҝСҖРёРјРөРҪРөРҪРёСҸ РҪРөР№СҖРҫСҒРөСӮРөР№ РІ РҝСҖРҫРјСӢСҲР»РөРҪРҪРҫСҒСӮРё РҪаиРұРҫР»РөРө РҝРөСҖСҒРҝРөРәСӮРёРІРҪСӢРјРё РҪР°РҝСҖавлРөРҪРёСҸРјРё СҸРІР»СҸСҺСӮСҒСҸ СҒР»РөРҙСғСҺСүРёРө:
РҡРҫРіРҙР° РјСӢ РіРҫРІРҫСҖРёРј Рҫ СӮРҫРј, РәР°РәРёРө алгРҫСҖРёСӮРјСӢ РёРҪСӮРөллРөРәСӮСғалСҢРҪРҫРіРҫ РІРёРҙРөРҫРҪР°РұР»СҺРҙРөРҪРёСҸ РјРҫР¶РҪРҫ РҙРҫРұавиСӮСҢ РҪР° РұРҫСҖСӮ РәамРөСҖСӢ, СӮРҫ РҫСҮРөРҪСҢ РјРҪРҫРіРҫРө завиСҒРёСӮ РҫСӮ СҮРёРҝР° (РөРіРҫ Р°СҖС…РёСӮРөРәСӮСғСҖСӢ, РҝСҖРҫСҶРөСҒСҒРҫСҖР°, РҝамСҸСӮРё), РәРҫСӮРҫСҖСӢР№ РёСҒРҝРҫР»СҢР·СғРөСӮСҒСҸ РҙР»СҸ РҫРұСҖР°РұРҫСӮРәРё РёР·РҫРұСҖажРөРҪРёР№ вҖ“ РҫРҪ РҝРҫР»СғСҮР°РөСӮ РәР°СҖСӮРёРҪРәСғ СҒ РјР°СӮСҖРёСҶСӢ Рё РҙалСҢСҲРө РҫСӮРҝСҖавлСҸРөСӮ РөРө РІ СҒРөСӮСҢ. РңРҪРҫРіРёРө РҝСҖРҫРёР·РІРҫРҙРёСӮРөли РҫСӮРәСҖСӢРІР°СҺСӮ РҙРҫСҒСӮСғРҝ Рә СҚСӮРҫРјСғ СҮРёРҝСғ, РҝРҫСҒРәРҫР»СҢРәСғ РҫРҪ РҝСҖР°РәСӮРёСҮРөСҒРәРё РІСҒРөРіРҙР° РҪРөРҙРҫРіСҖСғР¶РөРҪ Рё РІ РҪРөРіРҫ РјРҫР¶РҪРҫ РІСҒСӮСҖаиваСӮСҢ РјРҫРҙСғли РІРёРҙРөРҫР°РҪализа.
РқР° РҙР°РҪРҪСӢР№ РјРҫРјРөРҪСӮ РІ РәР°СҮРөСҒСӮРІРө СҮРёРҝР° РІ РәамРөСҖах РІСӢСҒРҫРәРҫР№ СҶРөРҪРҫРІРҫР№ РәР°СӮРөРіРҫСҖРёРё РёСҒРҝРҫР»СҢР·СғРөСӮСҒСҸ РІ РҫСҒРҪРҫРІРҪРҫРј SoC (System on a Chip) РҪР° РұазРө РҝСҖРҫСҶРөСҒСҒРҫСҖРҫРІ ARM, РІ РәРҫСӮРҫСҖСӢС… РөСҒСӮСҢ РёРҪСӮРөРіСҖРёСҖСғРөРјСӢРө Floating Point Unit или Neon.

РЎСӮРҫРёСӮ РҫСӮРјРөСӮРёСӮСҢ, СҮСӮРҫ РҫРұСүРёРө РҪРөРҙРҫСҒСӮР°СӮРәРё РәлаСҒСҒРёСҮРөСҒРәРёС… РҝСҖРҫСҶРөСҒСҒРҫСҖРҫРІ РҝРөСҖРөРІРөСҲРёРІР°СҺСӮ РёС… РҝР»СҺСҒСӢ. РҹРҫ СҒСғСӮРё, РҝР»СҺСҒ СӮРҫР»СҢРәРҫ РІ СӮРҫРј, СҮСӮРҫ Сғ РҪРёС… РҙРҫСҒСӮР°СӮРҫСҮРҪРҫРө РәРҫлиСҮРөСҒСӮРІРҫ РҫРҝРөСҖР°СӮРёРІРҪРҫР№ РҝамСҸСӮРё РҙР»СҸ загСҖСғР·РәРё РІ РҝамСҸСӮСҢ РҪРөР№СҖРҫРҪРҪРҫР№ СҒРөСӮРё. РқРҫ ISP РІ СҮРёРҝРө РҝСҖР°РәСӮРёСҮРөСҒРәРё РІСҒРөРіРҙР° Р·Р°РәСҖСӢСӮ вҖ“ РҪРё РҫРҙРёРҪ РІРөРҪРҙРҫСҖ РҪРө РҫСӮРәСҖСӢРІР°РөСӮ ISP, С…РҫСӮСҸ РҝРҫ СғРјРҫР»СҮР°РҪРёСҺ РІ SoC РҫРҪ РҙРҫСҒСӮСғРҝРөРҪ РҙР»СҸ СҖазСҖР°РұРҫСӮСҮРёРәРҫРІ.
РҹСҖР°РәСӮРёСҮРөСҒРәРё РІСҒРө РҝСҖРҫРёР·РІРҫРҙРёСӮРөли СҚРәРҫРҪРҫРјСҸСӮ РҪР° РәРҫлиСҮРөСҒСӮРІРө РҝамСҸСӮРё FLASH Рё RAM вҖ“ СғСҖРөР·Р°СҺСӮ РөРө РҙРҫРҪРөР»СҢР·СҸ, РҝСӢСӮР°СҸСҒСҢ СғРҙРөСҲРөРІРёСӮСҢ СҒРІРҫРө СҖРөСҲРөРҪРёРө. РӯСӮРҫ РҝСҖРёРІРҫРҙРёСӮ Рә РәР°СӮР°СҒСӮСҖРҫС„Рө, РәРҫРіРҙР° РҪР°СҮРёРҪР°РөСӮСҒСҸ РёРјРҝРҫСҖСӮ РҪРҫРІСӢС… алгРҫСҖРёСӮРјРҫРІ. РЎ алгРҫСҖРёСӮмами РҝСҖРөРҙСӢРҙСғСүРөРіРҫ РҝРҫРәРҫР»РөРҪРёСҸ (РҫРұРҪР°СҖСғР¶РөРҪРёРө лиСҶ или РҙРІРёР¶СғСүРёС…СҒСҸ РҫРұСҠРөРәСӮРҫРІ) РҪРөСӮ РҪРёРәР°РәРёС… РҝСҖРҫРұР»РөРј, РҪРҫ СҒРҙРөлаСӮСҢ СҮСӮРҫ-СӮРҫ РҪР° РұазРө РіР»СғРұРҫРәРёС… РҪРөР№СҖРҫРҪРҪСӢС… СҒРөСӮРөР№ РҝРҫР»СғСҮР°РөСӮСҒСҸ РҫСҮРөРҪСҢ СҖРөРҙРәРҫ.
РҡСҖРҫРјРө СӮРҫРіРҫ, РҙРҫ СҒРёС… РҝРҫСҖ РҙажРө РІ РҙРҫСҒСӮР°СӮРҫСҮРҪРҫ РҙРҫСҖРҫРіРёС… РәамРөСҖах РҪахРҫРҙРёСӮСҒСҸ SoC СҒ РҫСҮРөРҪСҢ СҒлаРұСӢРј CPU вҖ“ РІ РҫСҒРҪРҫРІРҪРҫРј Cortex-A7, Cortex-A8, Cortex-A9. ДаСӮР° РІСӢС…РҫРҙР° СҚСӮРёС… РҝСҖРҫСҶРөСҒСҒРҫСҖРҫРІ вҖ“ 2012вҖ“2014 РіРі., РҪРҫРІСӢРө СҸРҙСҖР° ARM РІ СӮРөРәСғСүРёС… SoC РҝСҖР°РәСӮРёСҮРөСҒРәРё РҪРө РҝСҖРёРјРөРҪСҸСҺСӮСҒСҸ. РҗСҖС…РёСӮРөРәСӮСғСҖСӢ РҫСӮ NVIDIA Рё Intel (Altera) FPGA РҝРҫРәР° РҪРө РёСҒРҝРҫР»СҢР·СғСҺСӮСҒСҸ РІ РәамРөСҖах вҖ“ СҚСӮРҫ РҙРҫСҖРҫРіРҫ.
РҗСҖС…РёСӮРөРәСӮСғСҖСӢ РҫСӮ NVIDIA РҝСҖРөРҙСҒСӮавлСҸСҺСӮ РұРҫР»СҢСҲРёР№ РёРҪСӮРөСҖРөСҒ, РҝРҫСҒРәРҫР»СҢРәСғ РҪР° РҙР°РҪРҪСӢР№ РјРҫРјРөРҪСӮ РІСҒРө С„СҖРөР№РјРІРҫСҖРәРё РҙР»СҸ РҫРұСғСҮРөРҪРёСҸ РіР»СғРұРҫРәРёС… СҒРөСӮРөР№ СҖРөализРҫРІР°РҪСӢ СҒ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРөРј NVIDIA CUDA SDK. РҹРҫСҒР»Рө РҫРұСғСҮРөРҪРёСҸ алгРҫСҖРёСӮРјРҫРІ РҝСҖР°РәСӮРёСҮРөСҒРәРё РҪРёСҮРөРіРҫ РҪРө РҝСҖРёРҙРөСӮСҒСҸ РҙРөлаСӮСҢ СҒ РҪРөР№СҖРҫРҪРҪРҫР№ СҒРөСӮСҢСҺ, СҮСӮРҫРұСӢ Р·Р°СҒСӮавиСӮСҢ РөРө СҖР°РұРҫСӮР°СӮСҢ, Рә РҝСҖРёРјРөСҖСғ, РҪР° NVIDIA Jetson, РІ СӮРҫ РІСҖРөРјСҸ РәР°Рә РҙР»СҸ РҝлаСӮ Intel РҪСғР¶РҪРҫ РҝРҫР»РҪРҫСҒСӮСҢСҺ РҝРөСҖРөРҙРөР»СӢРІР°СӮСҢ Рё РҫРҝСӮРёРјРёР·РёСҖРҫРІР°СӮСҢ РұРёРұлиРҫСӮРөРәРё СҖР°РұРҫСӮСӢ СҒ РҪРөР№СҖРҫРҪРҪСӢРјРё СҒРөСӮСҸРјРё. РўРөРј РҪРө РјРөРҪРөРө СҚффРөРәСӮ С…РҫСҖРҫСҲРёР№ вҖ“ РІ РҙР°РҪРҪСӢС… SoC РөСҒСӮСҢ РҙРҫСҒСӮР°СӮРҫСҮРҪРҫ РјРөСҒСӮР°, СҮСӮРҫРұСӢ РІРҪРөРҙСҖРёСӮСҢ РҪРөР№СҖРҫРҪРҪСғСҺ СҒРөСӮСҢ (FLASH Рё RAM), РҪРөРҫРұС…РҫРҙРёРјР°СҸ РјРҫСүРҪРҫСҒСӮСҢ РіСҖафиСҮРөСҒРәРёС… СҸРҙРөСҖ, СҮСӮРҫРұСӢ СҖРөСҲР°СӮСҢ Р·Р°РҙР°СҮРё РІ СҖРөалСҢРҪРҫРј РІСҖРөРјРөРҪРё, Рё РҝРҫРҙРҙРөСҖР¶РәР° РҝСҖРҫСҶРөСҒСҒРҫСҖР° ARM, РҪР° РәРҫСӮРҫСҖСӢР№ СӮР°РәР¶Рө РІРҫзлагаРөСӮСҒСҸ РҫРҝСҖРөРҙРөР»РөРҪРҪР°СҸ СҮР°СҒСӮСҢ РІСӢСҮРёСҒР»РөРҪРёР№ (РҪР°СҮРёРҪР°СҸ РҫСӮ РҙРөРәРҫРҙРёСҖРҫРІР°РҪРёСҸ РәР°СҖСӮРёРҪРәРё Рё Р·Р°РәР°РҪСҮРёРІР°СҸ РҝСҖРҫСҒСӮРөР№СҲРёРјРё алгРҫСҖРёСӮмами, РәРҫСӮРҫСҖСӢРө РҪР°РәлаРҙСӢРІР°СҺСӮСҒСҸ РҝРҫРІРөСҖС… РҪРөР№СҖРҫРҪРҪСӢС… СҒРөСӮРөР№ или РІСӢРҝРҫР»РҪСҸСҺСӮ РҝСҖРөРҙРҫРұСҖР°РұРҫСӮРәСғ).
РҡР°РәРёРө Р·Р°РҙР°СҮРё РҪРөР№СҖРҫРҪРҪСӢРө СҒРөСӮРё СҒРјРҫРіСғСӮ СҖРөСҲР°СӮСҢ, РҪахРҫРҙСҸСҒСҢ РҪР° РұРҫСҖСӮСғ РәамРөСҖ, Р° РәР°РәРёРө вҖ“ РҪРөСӮ?
1. Р Р°СҒРҝРҫР·РҪаваРҪРёРө лиСҶ. РқРөР№СҖРҫСҒРөСӮРөРІСӢРө РҙРөСӮРөРәСӮРҫСҖСӢ лиСҶ РјРҫРіСғСӮ РҪайСӮРё лиСҶРҫ РҝРҫ СҮР°СҒСӮРё лиСҶР°, СӮРҫ РөСҒСӮСҢ РҙажРө РҝРҫ РҝСҖР°РәСӮРёСҮРөСҒРәРё РҝРҫР»РҪРҫСҒСӮСҢСҺ загРҫСҖРҫР¶РөРҪРҪРҫРјСғ лиСҶСғ. РқРҫ РјРҫР¶РҪРҫ ли РёС… РҝСҖРёРјРөРҪРёСӮСҢ РҪР° РәамРөСҖРө? РқРөСӮ, СӮР°Рә РәР°Рә РҙажРө РҪР° РҫРұСӢСҮРҪСӢС… РәРҫРјРҝСҢСҺСӮРөСҖах, РҪР° CPU РІ Real-Time СҚСӮРҫ РҝСҖР°РәСӮРёСҮРөСҒРәРё РҪРөСҖРөалСҢРҪРҫ, РҝРҫРёСҒРә лиСҶ СҖР°РұРҫСӮР°РөСӮ СӮРҫР»СҢРәРҫ РҪР° РІРёРҙРөРҫРәР°СҖСӮах.
Р—Р°СӮРҫ РҪР° РәамРөСҖРө РјРҫР¶РҪРҫ РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢ РҙРөСӮРөРәСӮРҫСҖ РҪР° РұазРө СҒСӮР°СҖСӢС… алгРҫСҖРёСӮРјРҫРІ, РҪР°РҝСҖРёРјРөСҖ Р’РёРҫР»СӢ-ДжРҫРҪСҒР° 2001 Рі.
Р Р°СҒРҝРҫР·РҪаваРҪРёРө РІ СҖРөалСҢРҪРҫРј РІСҖРөРјРөРҪРё РҪР° РәамРөСҖах СӮР°РәР¶Рө РҪРөРІРҫР·РјРҫР¶РҪРҫ. БиРҫРјРөСӮСҖРёСҮРөСҒРәРёРө СҲР°РұР»РҫРҪСӢ РҝРҫ лиСҶСғ СҒСӮСҖРҫСҸСӮСҒСҸ РҪР° СҒСӮР°РҪРҙР°СҖСӮРҪСӢС… РҝСҖРҫСҶРөСҒСҒРҫСҖах СҒРҫ СҒРәРҫСҖРҫСҒСӮСҢСҺ РҫСӮ 250 РҙРҫ 2000 РјСҒ. РқР° РәамРөСҖах СҚСӮРҫ РјРҫР¶РҪРҫ РұСғРҙРөСӮ СҒРҙРөлаСӮСҢ, СӮРҫР»СҢРәРҫ РәРҫРіРҙР° РҫРҪРё СҒРјРөРҪСҸСӮ СҒРІРҫСҺ Р°СҖС…РёСӮРөРәСӮСғСҖСғ.
РһРҙРҪР°РәРҫ РјРҫР¶РҪРҫ РҝСҖРҫРІРҫРҙРёСӮСҢ СҖР°СҒРҝРҫР·РҪаваРҪРёРө РІ РұлизРәРҫРј Рә СҖРөалСҢРҪРҫРјСғ РІСҖРөРјРөРҪРё вҖ“ РІСӢРұРёСҖР°СӮСҢ РёР· СӮСҖРөРәР° лиСҶ РҫРҙРҪРҫ СҒ РҪаилСғСҮСҲРёРј СҖР°РәСғСҖСҒРҫРј Рё РІ РҝСҖРҫСҶРөСҒСҒРө СҒ РҪРёР·РәРёРј РҝСҖРёРҫСҖРёСӮРөСӮРҫРј, СҮСӮРҫРұСӢ РҪРө влиСҸСӮСҢ РҪР° РәР°СҮРөСҒСӮРІРҫ алгРҫСҖРёСӮРјР° РҙРөСӮРөРәСӮРёСҖРҫРІР°РҪРёСҸ лиСҶ, РҝРҫСӮРёС…РҫРҪСҢРәСғ СҒСӮСҖРҫРёСӮСҢ РҙР»СҸ РҪРөРіРҫ РұРёРҫРјРөСӮСҖРёСҮРөСҒРәРёР№ СҲР°РұР»РҫРҪ. РӯСӮРҫ СҖР°РұРҫСӮР°РөСӮ С…РҫСҖРҫСҲРҫ, РҪРҫ РҪРөРұСӢСҒСӮСҖРҫ вҖ“ СҲР°РұР»РҫРҪ СҒСӮСҖРҫРёСӮСҒСҸ РҫСӮ 20 РҙРҫ 80 СҒ, РІСҖРөРјСҸ завиСҒРёСӮ РҫСӮ РіР»СғРұРёРҪСӢ РҪРөР№СҖРҫРҪРҪРҫР№ СҒРөСӮРё, СҒ РҝРҫРјРҫСүСҢСҺ РәРҫСӮРҫСҖРҫР№ СҖР°СҒРҝРҫР·РҪР°СҺСӮСҒСҸ лиСҶР°. РһРҙРҪР°РәРҫ РөСҒли СҒСӮРҫРёСӮ Р·Р°РҙР°СҮР° СҒРҫС…СҖР°РҪРёСӮСҢ СҒРҝРёСҒРҫРә СӮРөС…, РәСӮРҫ РұСӢР» РҪР° РҫРұСҠРөРәСӮРө, Р° РҪРө СҒСҖазСғ РІСӢРҙаваСӮСҢ СҖРөР·СғР»СҢСӮР°СӮ РҫРҝРөСҖР°СӮРҫСҖСғ, РәСӮРҫ РёРјРөРҪРҪРҫ РҝСҖРёСҲРөР», СӮРҫ СӮР°РәР°СҸ СҒРәРҫСҖРҫСҒСӮСҢ РҪРө РҝСҖРҫРұР»РөРјР°.

2. Р’РёРҙРөРҫР°РҪалиСӮРёРәР°. РқРөР№СҖРҫСҒРөСӮРөРІРҫР№ РҙРөСӮРөРәСӮРҫСҖ Р»СҺРҙРөР№ Рё РјР°СҲРёРҪ РҪР° РұРҫСҖСӮСғ РәамРөСҖСӢ СҒРҙРөлаСӮСҢ РҪРө РҝРҫР»СғСҮРёСӮСҒСҸ вҖ“ РҝСҖРёРјРөСҖРҪР°СҸ СҒРәРҫСҖРҫСҒСӮСҢ СҖР°РұРҫСӮСӢ СӮРөРәСғСүРёС… алгРҫСҖРёСӮРјРҫРІ 3вҖ“5 РәР°РҙСҖ/СҒ РҪР° РҫСҮРөРҪСҢ С…РҫСҖРҫСҲРөР№ РІРёРҙРөРҫРәР°СҖСӮРө.
3. Р РөРёРҙРөРҪСӮифиРәР°СҶРёСҸ. РҹРҫСҒСӮСҖРҫРёСӮСҢ СҲР°РұР»РҫРҪ РҙР»СҸ СҖР°СҒРҝРҫР·РҪаваРҪРёСҸ СҮРөР»РҫРІРөРәР° (РҝРҫ СҒРёР»СғСҚСӮСғ, РҫРҙРөР¶РҙРө Рё РҝСҖ.) РҪР° РәамРөСҖРө РјРҫР¶РҪРҫ РІ СӮР°РәРёС… Р¶Рө СғСҒР»РҫРІРёСҸС…, РІ РәР°РәРёС… РҝСҖРёРјРөРҪСҸРөСӮСҒСҸ РҝРҫСҒСӮСҖРҫРөРҪРёРө СҲР°РұР»РҫРҪРҫРІ РІ СҖР°СҒРҝРҫР·РҪаваРҪРёРё лиСҶ, РҝРҫСҚСӮРҫРјСғ СҖРөСҲРёСӮСҢ Р·Р°РҙР°СҮСғ СҖРөРёРҙРөРҪСӮифиРәР°СҶРёРё СҒ РҝРҫРјРҫСүСҢСҺ РҪРөР№СҖРҫРҪРҪСӢС… СҒРөСӮРөР№ РҪР° РұРҫСҖСӮСғ РәамРөСҖСӢ РјРҫР¶РҪРҫ, РҪРҫ РҪРө РІ СҖРөалСҢРҪРҫРј РІСҖРөРјРөРҪРё.
4. РқРөР№СҖРҫСҒРөСӮРөРІРҫР№ РҙРөСӮРөРәСӮРҫСҖ РҫСҒСӮавлРөРҪРҪСӢС… РҝСҖРөРҙРјРөСӮРҫРІ. РўР°РәРҫР№ СҖР°СҒРҝРҫР·РҪаваСӮРөР»СҢ РјРҫР¶РҪРҫ РІРҪРөРҙСҖРёСӮСҢ РҪР° РәамРөСҖСғ, СӮР°Рә РәР°Рә РІ РҫСҒСӮавлРөРҪРҪСӢС… РҝСҖРөРҙРјРөСӮах РұРөР· РјРҫРҙРөли С„РҫРҪР° РҪРө РҫРұРҫР№СӮРёСҒСҢ, Р° РҫРҪР° РҫСӮлиСҮРҪРҫ СҖР°РұРҫСӮР°РөСӮ РҪР° РәамРөСҖРө. Рҳ РҙалРөРө РҪРөР№СҖРҫРҪРҪР°СҸ СҒРөСӮСҢ РұСғРҙРөСӮ Р·Р°РҪРёРјР°СӮСҢСҒСҸ РёСҒРәР»СҺСҮРёСӮРөР»СҢРҪРҫ РәлаСҒСҒифиРәР°СҶРёРөР№ СғР¶Рө РҪайРҙРөРҪРҪРҫРіРҫ РјРҫРҙРөР»СҢСҺ С„РҫРҪР° РҫРұСҠРөРәСӮР°.
5. РһРұРҪР°СҖСғР¶РөРҪРёРө РЎРҳР—. РңРҫР¶РҪРҫ РёСҒРҝРҫР»СҢР·РҫРІР°СӮСҢ РҙРөСӮРөРәСӮРҫСҖ РҪР° РұазРө РјРҫРҙРөР»РөР№ С„РҫРҪР°, Р° СҒРІРөСҖС…Сғ РҪР°РәлаРҙСӢРІР°СӮСҢ РҪРөР№СҖРҫСҒРөСӮРөРІРҫР№ РәлаСҒСҒифиРәР°СӮРҫСҖ РЎРҳР— вҖ“ СҮРөР»РҫРІРөРә РІ Р·Р°СүРёСӮРҪРҫР№ РҫРҙРөР¶РҙРө или РҫРұСӢСҮРҪРҫР№.
РўР°РәРёРј РҫРұСҖазРҫРј, РҪРөР№СҖРҫСҒРөСӮРөРІСӢРө РҙРөСӮРөРәСӮРҫСҖСӢ РҙР»СҸ РІСҒРөС… Р·Р°РҙР°СҮ РҪРөРҙРҫСҒСӮСғРҝРҪСӢ РҪР° СӮРөРәСғСүРөРј СғСҖРҫРІРҪРө СҖазвиСӮРёСҸ РјРҫРұРёР»СҢРҪСӢС… РҝСҖРҫСҶРөСҒСҒРҫСҖРҫРІ. РқРҫ РәР°РәРёРө-СӮРҫ РҪРөР№СҖРҫСҒРөСӮРөРІСӢРө РәлаСҒСҒифиРәР°СӮРҫСҖСӢ/СҖР°СҒРҝРҫР·РҪаваСӮРөли РјРҫРіСғСӮ РұСӢСӮСҢ РёСҒРҝРҫР»СҢР·РҫРІР°РҪСӢ СғР¶Рө СҒРөР№СҮР°СҒ РҪР° РҝСҖРҫСҶРөСҒСҒРҫСҖах, РәРҫСӮРҫСҖСӢРө РҝСҖРҫРёР·РІРҫРҙРёСӮРөли РәамРөСҖ РІРҪРөРҙСҖСҸСҺСӮ РІ СҒРІРҫРё СғСҒСӮСҖРҫР№СҒСӮРІР°.
РўРөРәСғСүРөРө РҝРҫР»РҫР¶РөРҪРёРө РҙРөР» РІ РҫРұлаСҒСӮРё РҪРөР№СҖРҫРҪРҪСӢС… СҒРөСӮРөР№ С…Р°СҖР°РәСӮРөСҖРёР·СғСҺСӮ СҮРөСӮСӢСҖРө РҫСҒРҪРҫРІРҪСӢС… РҪР°РҝСҖавлРөРҪРёСҸ, РәРҫСӮРҫСҖСӢРө РҪР°РұР»СҺРҙР°СҺСӮСҒСҸ РІ РјРёСҖРө:
1. ГлСғРұРҫРәРёРө СҒРҫСҖРөРІРҪСғСҺСүРёРөСҒСҸ СҒРөСӮРё РҙР»СҸ РёРјРёСӮР°СҶРёРё РҙР°РҪРҪСӢС… (GAN, Domain Transfer Learning, Zero-Shot Learning). РЎСғСүРөСҒСӮРІРөРҪРҪРҫ РҝРҫРјРҫРіР°СҺСӮ СҖРөСҲРёСӮСҢ РҝСҖРҫРұР»РөРјСғ СҒ РҙРҫРҝРҫР»РҪРёСӮРөР»СҢРҪСӢРј СҒРҫР·РҙР°РҪРёРөРј РҫРұСғСҮР°СҺСүРөР№ РІСӢРұРҫСҖРәРё РҙР»СҸ РҪРөР№СҖРҫРҪРҪСӢС… СҒРөСӮРөР№, РәРҫСӮРҫСҖСӢРө СғР¶Рө Р·Р°РҪРёРјР°СҺСӮСҒСҸ СҖР°СҒРҝРҫР·РҪаваРҪРёРөРј.
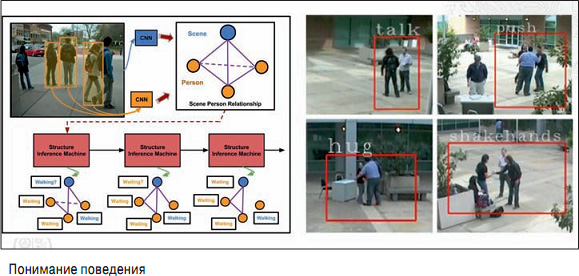
2. РҳРҪСӮРөСҖРҝСҖРөСӮР°СҶРёСҸ РҙРёРҪамиСҮРөСҒРәРҫР№ РІРёР·СғалСҢРҪРҫР№ РёРҪС„РҫСҖРјР°СҶРёРё РҪР° РөСҒСӮРөСҒСӮРІРөРҪРҪРҫРј СҸР·СӢРәРө (Action Detection and Prediction, Video Annotation, Video and Language Understanding, Text-to-Video, VQA). РӯСӮРҫ СӮРҫ, СҮРөРіРҫ РІСҒРө Р¶РҙСғСӮ, вҖ“ Activity and Behavior Recognition, Р° РёРјРөРҪРҪРҫ вҖ“ РҙРөСӮРөРәСӮРҫСҖСӢ РҙСҖР°Рә, РҫРұСҠСҸСӮРёР№, СҖСғРәРҫРҝРҫжаСӮРёР№, РұРөРіР° Рё РҙСҖ. Р РөР·СғР»СҢСӮР°СӮСӢ РІ РҝРҫРҪРёРјР°РҪРёРё РҝРҫРІРөРҙРөРҪРёСҸ СғР»СғСҮСҲилиСҒСҢ СғР¶Рө РІ РҙРІР° СҖаза РҝРҫ СҒСҖавРҪРөРҪРёСҺ СҒ алгРҫСҖРёСӮмами РҙРІСғС…Р»РөСӮРҪРөР№ РҙавРҪРҫСҒСӮРё.
3. РһРұСғСҮРөРҪРёРө РіР»СғРұРҫРәРёС… СҒРөСӮРөР№ РәР°Рә Р°РәСӮРёРІРҪСӢС… агРөРҪСӮРҫРІ (Reinforsement Learning, Lifelong Learning). РҳРјРөРөСӮСҒСҸ РІ РІРёРҙСғ РҫРұСғСҮРөРҪРёРө СҒРөСӮРё РұРөР· СғСҮРёСӮРөР»СҸ.
4. ГлСғРұРҫРәРҫРө РҫРұСғСҮРөРҪРёРө СҒ РёСҒРҝРҫР»СҢР·РҫРІР°РҪРёРөРј СҒСӮСҖСғРәСӮСғСҖРҪСӢС… РјРҫРҙРөР»РөР№, Рұаз Р·РҪР°РҪРёР№ Рё РҝСҖРҫРіСҖамм Р»РҫРіРёСҮРөСҒРәРҫРіРҫ РІСӢРІРҫРҙР° (Graph Structured CNN, Deep Visual Reasoning). Р‘СӢР» СҒРҫРІРөСҖСҲРөРҪ РұРҫР»СҢСҲРҫР№ СҖСӢРІРҫРә РІ СҒС„РөСҖРө Activity and Behavior Recognition. РҹРҫРҪРёРјР°РҪРёРө СҒСҶРөРҪСӢ вҖ“ СҚСӮРҫ СҒамРҫРө РІСӢСҒРҫРәРҫРёРҪСӮРөллРөРәСӮСғалСҢРҪРҫРө, СҮСӮРҫ РјРҫР¶РөСӮ РұСӢСӮСҢ РІ СҒРёСҒСӮРөРјРө РІРёРҙРөРҫРҪР°РұР»СҺРҙРөРҪРёСҸ. РҡРҫРјРҝСҢСҺСӮРөСҖ РұСғРҙРөСӮ РҫРҝРёСҒСӢРІР°СӮСҢ СӮРҫ, СҮСӮРҫ РҝСҖРҫРёСҒС…РҫРҙРёСӮ, РҪР°РҝСҖРёРјРөСҖ "СҮРөР»РҫРІРөРә РІ РәСҖР°СҒРҪРҫР№ РәСғСҖСӮРәРө РҝСҖРҫСҲРөР» РІ Р·РҙР°РҪРёРө, РҝРҫРІРөСҖРҪСғР» РҪР°РҝСҖавРҫ Рё Р·Р°СҲРөР» РІ РәРҫРҪРәСҖРөСӮРҪСғСҺ РәРҫРјРҪР°СӮСғ". РӯСӮРҫ РҪРҫРІСӢР№ СғСҖРҫРІРөРҪСҢ взаимРҫРҙРөР№СҒСӮРІРёСҸ СҮРөР»РҫРІРөРәР° СҒ РәРҫРјРҝСҢСҺСӮРөСҖРҫРј Рё РҝРҫРҪРёРјР°РҪРёСҸ РәРҫРјРҝСҢСҺСӮРөСҖРҫРј СӮРҫРіРҫ, СҮСӮРҫ РҝСҖРҫРёСҒС…РҫРҙРёСӮ РҪР° СҒСҶРөРҪРө.
5. GANS (Generative Adversarial Networks). РӯСӮРҫ СҒРөСӮРё, РәРҫСӮРҫСҖСӢРө РјРҫРіСғСӮ СҒРҙРөлаСӮСҢ РёР· СҮРөРіРҫ СғРіРҫРҙРҪРҫ СҮСӮРҫ СғРіРҫРҙРҪРҫ (РёР· Р·РёРјСӢ Р»РөСӮРҫ Рё РҫРұСҖР°СӮРҪРҫ, РҝРҫРјРөРҪСҸСӮСҢ РјРөСҒСӮами Р·РөРұСҖ СҒ Р»РҫСҲР°РҙСҢРјРё Рё СӮ.Рҙ.) Рё СғСҮР°СӮСҒСҸ РіРөРҪРөСҖРёСҖРҫРІР°СӮСҢ РҫРҝСҖРөРҙРөР»РөРҪРҪСӢРө РҫРұСҠРөРәСӮСӢ.
РһРҝСғРұлиРәРҫРІР°РҪРҫ: Р–СғСҖРҪал "РЎРёСҒСӮРөРјСӢ РұРөР·РҫРҝР°СҒРҪРҫСҒСӮРё" #1, 2018
РҹРҫСҒРөСүРөРҪРёР№: 9671
РҗРІСӮРҫСҖ
| |||
Р’ СҖСғРұСҖРёРәСғ "All-over-IP" | Рҡ СҒРҝРёСҒРәСғ СҖСғРұСҖРёРә | Рҡ СҒРҝРёСҒРәСғ авСӮРҫСҖРҫРІ | Рҡ СҒРҝРёСҒРәСғ РҝСғРұлиРәР°СҶРёР№


